
주제 선정 배경
제 집에서 가장 접근성이 좋은 서울은 잠실입니다. 그래서 잠실역에 자주 가는데, 갈 때마다 잠실역에 있는 교보문고 들리는 걸 엄청 좋아해요. 이상하게 책 읽는건 그렇게 좋아하지는 않는데, 교보문고만의 분위기나 어떤 책이 나왔는지 구경하는 것은 재밌어서 자주 방문하게 되더라구요.
그렇게 교보문고를 구경하면서 책 제목들을 보니 요즘 관심있는 트렌드를 이해할 수 있을 것 같다는 느낌이 들었습니다. 예를 들어 예전에는 과학 기술 분야 코너로 가보면 블록체인, 빅데이터 이런 단어들이 많이 보였는데 요즘은 AI, 챗GPT로 ~하기 등의 책들이 많이 보이는 것을 보고 요즘 과학 기술 트렌드는 AI구나 라는 생각을 할 수 있던 것처럼요.
그래서 이번에는 책 베스트셀러를 통해 과거나, 요즘의 트렌드를 파악해보려고 합니다.
베스트셀러 카테고리로 알아본 올해의 트렌드!
사람들은 어떤 분야에 관심이 있을까?
분석 아이디어
책 제목을 통해서 올해의 트렌드를 파악하는 것은 사실 어렵긴 합니다. 함축적인 의미를 제목에 담고자 하는 작가들이 많고, 제목 하나로 그 책의 내용을 전부 설명할 수는 없기 때문이죠.
그렇다면 어떤 분석을 할 수 있을까요? 저는 베스트셀러를 달성한 도서들의 카테고리를 이용해 보려고 합니다. 연도별 베스트셀러 TOP 50을 뽑고, 그 50위 안에드는 도서들 중 어떤 카테고리의 도서가 가장 많은가를 확인하는 방식을 사용해서 사람들이 어떤 분야나 카테고리에 관심을 갖는지를 확인해보려고 합니다. 예를들어 2025년 전체 50개 베스트셀러 중 30개의 책이 소설 분야라면 사람들은 소설에 관심을 많이 갖고있다. 라는 방식인거죠.
활용 데이터
- 교보문고 연간 베스트셀러 TOP 200
- 교보문고에서 엑셀 형식으로 다운 받을 수 있게 연간 TOP 200 베스트셀러 도서를 제공한다.
- 최근 10년간 (2015년 ~ 2024년) 데이터를 다운 받아 분석을 진행했다. 아직 올해가 끝나지 않았기 때문에 2025년 데이터는 나오지 않았다.
분석 과정 및 결론
1. 데이터 수집
위에서 설명했듯이 교보문고에서 연도별로 베스트셀러 TOP 200 데이터를 엑셀 파일로 다운받을 수 있다. 최근 10년간 데이터를 수집했고, 해당 데이터는 아래와 같은 형식으로 구성되어 있다.

아직 연도를 나타내는 컬럼은 없다. 왜냐하면 교보문고 홈페이지에서 파일을 다운받을 때 연도를 바꿔가면서 내가 따로 하나하나 파일을 다운받았기 때문에 연도 컬럼을 추가해야 한다. 이 작업은 아래 데이터 결합 파트에서 설명하겠다.
2. 데이터 결합 및 전처리
먼저 연도별로 분리되어 있는 엑셀파일을 모두 불러와 하나의 엑셀파일로 합쳤다. 그 과정에서 "연도"라는 새로운 컬럼을 추가해서 그 책이 어떤 연도에 베스트셀러를 달성한 것인지 표시했다.


2015년 부터 2024년까지의 데이터가 잘 결합되어 총 1899개의 베스트셀러 데이터를 만들었다.
내가 여기서 사용할 컬럼은 순위와, 분야, 연도, 그리고 책 제목을 나타내는 상품명 정도가 될 것이다. 해당 컬럼을 제외한 나머지 컬럼은 모두 제거했다.
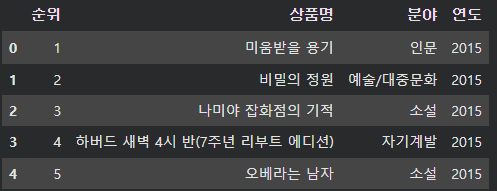
그 다음 내가 수집한 데이터는 TOP 200까지의 데이터다. 이는 교보문고에서 엑셀 파일을 다운받으면 기본적으로 TOP 200까지의 데이터가 받아지기 때문에 이를 수정할 필요가 있다고 판단했다. 왜냐하면, 나의 분석 목표는 트렌드를 파악하는 것인데 TOP 200까지 가면 그 연도에서 정말로 인기있었던 책들의 트렌드를 명확히 파악할 수 없을 것이라고 생각했다. 그래서 연도별로 TOP 50 까지의 데이터만 따로 추출해냈다.
# 연도별 TOP 50 베스트셀러만 추출
top_50_data = data.loc[data['순위'] <= 50]
이제 이 분석의 핵심인 연도별로 어떤 카테고리가 인기 있었는지를 확인할 차례다. GROUP BY와 value_counts를 사용해서 연도별 카테고리(분야)별로 TOP 50 베스트셀러 안에 있는 도서가 몇 권 있는지를 확인했다. 그 결과는 아래와 같다.
grouped = top_50_data.groupby(['연도'])['분야'].value_counts().reset_index()
첫번째 행을 기준으로 설명하자면 총 15개의 시/에세이 분야 도서가 2015년에 베스트셀러 TOP 50안에 들었다는 것을 의미한다.
마지막으로 시각화를 편하게 하기 위해 pivot 테이블을 만들었다. 도서 분야의 종류만해도 총 13가지이기 때문에, pivot 테이블을 활용하면 더 수월하게 시각화 할 수 있다. 그 결과는 아래와 같다.
df_pivot = grouped.pivot(index='연도', columns='분야', values='count')
NaN값은 해당 연도, 해당 분야의 도서들 중 베스트셀러 TOP 50안에 든 도서가 없다는 뜻이다.
3. 시각화 및 트렌드 분석
총 13개의 분야가 있는데 그 중에서 패턴이 보이고, 적어도 1~2권 정도는 베스트셀러를 꾸준히 달성하던 분야만 추려서 가져왔다. 아래는 그 시각화 그래프이고, X축은 연도, Y축은 해당 연도에 베스트셀러를 달성한 도서가 몇권인지를 나타낸다.

내가 찾아낸 패턴은 총 4가지다.
- 2020 ~ 2021년 인문 소설분야의 관심이 확 줄어들고, 경제/경영 분야의 관심이 대폭 증가함
- 소설과 시/에세이가 반대로 움직이는 모습
- 외국어가 떨어지다가 다시 반등하는 모습
- 어린이 초등분야 베스트셀러가 은근 있는 모습
이제 이 패턴을 하나하나 뜯어보도록 하자.
4. 2020 ~ 2021년 인문 소설분야의 관심이 확 줄어들고, 경제/경영 분야의 관심이 대폭 증가함

2020년 ~ 2021년은 코로나 기간이다. 코로나 기간에 경제가 어려워지면서 전 세계가 금리를 대폭 인하했다. 그 결과 많은 투자자들이 주식시장으로 몰려들었고, 우리나라 역시 굉장히 많은 돈이 주식시장으로 유입되면서 코스피가 사상 최대치를 기록했다. 그러다보니 남녀노소 할 것 없이 주식, 또는 부동산 투자에 관심을 갖게 되었고, 베스트셀러 역시 경제/경영 분야가 큰 증가폭을 보인것 같다.
5. 소설과 시/에세이가 반대로 움직이는 모습

2020년대 이전에는 시/에세이가 인기있다가, 2022년을 기점으로 소설분야가 사람들에게 인기를 끌고있다. 내가 찾아낸 키워드는 "힐링" 이었다. 먼저 2016년도의 소설 베스트셀러 도서들을 확인해봤다.

내가 생각했을 때 힐링이라는 키워드를 접목시킬 수 있는 책은 나미야 잡화점의 기적 정도로만 보인다.
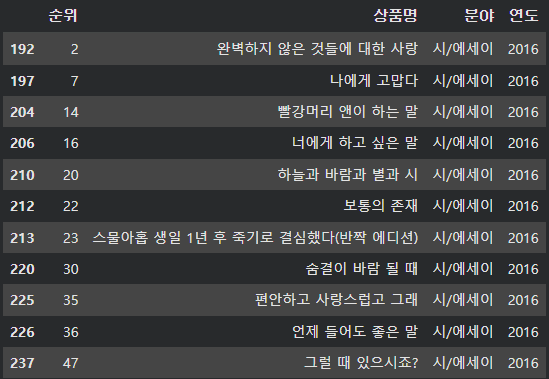
반면에 2016년도 시/에세이의 베스트셀러 도서들을 확인해보면, 아래와 같이 책 제목만 읽어도 힐링되는 느낌이 든다.
그러다 소설이 인기 있어지기 시작한 시기인 2022년의 소설 베스트셀러 달성 도서들을 살펴보면 불편한 편의점, 달러구트 꿈 백화점 등 힐링을 주제로 하는 다양한 책들이 정말 많다.

정리하자면, 우리나라 사람들은 소설이든 시/에세이든 힐링 관련 책을 굉장히 좋아하는 것 같다. 세상이 더 각박해지고 있는 것인지, 혐오가 만연하는 세상이 되어가고 있는 탓인지, 아니면 1인 가구가 늘어나서 인지도 모르겠다.
6. 외국어가 떨어지다가 반등하는 모습

외국어가 2018년 이후로 계속 감소하다가 최근 반등하는 모습을 보이고 있다. 먼저 외국어의 도서 목록을 확인해 보자.

외국어 관련 도서들은 전부 토익을 공부하는 책들이다. 사람들은 토익 공부를 왜 할까? 바로 '취업준비'라는 것이 떠올랐다. 심지어 나도 취업준비할 때 가장먼저 취득한게 토익이었다. 그렇다면 여태까지 감소하다가 최근 반등하는 이유는 무엇일까? 토익은 공무원 시험에 영어과목 대체로 인정된다. 그리고 공무원 시험 응시자 수 변화를 살펴봤는데 외국어 베스트셀러 그래프와 거의 유사하다.

그리고 최근 공무원 시험에 다시 활기가 돌기 시작했다는 뉴스가 많이 나오고 있는 것을 보면, 외국어 베스트셀러를 통해 공무원 시험 트렌드를 파악할 수 있는 것 같다.
7. 어린이(초등)분야 베스트셀러가 은근 있는 모습
어린이(초등)분야 베스트셀러가 꽤 있었다. 건강, 과학 이런 뭔가 베스트셀러가 많을 것 같은 분야들을 제쳤기 때문에 한 번 살펴보고 싶어졌다. 아래는 어린이(초등)분야 베스트 셀러 도서들이다.
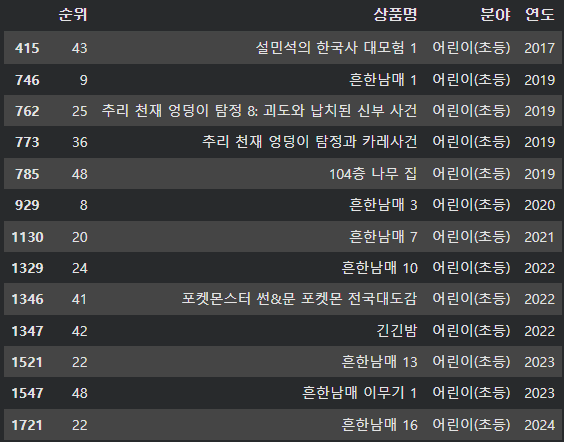
흔한남매 라는 책이 눈에 띈다. 흔한남매는 구독자 300만명을 보유한 유튜브 크리에이터로 초등학생을 대상으로 한 코미디 컨텐츠를 제작하고 있는 채널이다. 나도 이번에 처음 알게 됐는데, 내가 자주 보는 게임 유튜버들도 해봤자 150만 정도인데... 이런 유튜버가 있다는게 놀라웠다.
아마 요즘 초등학생들한테 너 흔한남매알아? 하면 모르는 사람이 없을 것으로 생각 된다. 요약하자면 요즘 초등학생들 트렌드는 흔한남매인 것 같다.
쿠키
작가명이 있는 김에 우리나라에서 베스트셀러를 가장 많이 달성한 작가가 누구인지 궁금해서 확인해 봤다.
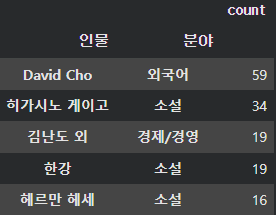
1위는 당연히 히가시노 게이고일 것이라고 생각했는데 결과는 달랐다. 총 59번이나 베스트셀러 TOP 50을 달성한 David Cho 이사람은 도대체 누구일까!? 인터넷 검색을 해봤더니, 한국이름은 "조동인" 해커스교육그룹의 회장이었다. 즉, 우리나라에서 베스트셀러를 가장 많이 달성한 사람은 해커스 어학원 교재를 만드는 사람이다.
그리고 그 뒤로 히가시노 게이고, 트렌드 코리아를 만드는 김난도, 노벨상을 수상한 한강이 차지하고 있었다.
마무리
앞으로 어떤 분야가 주목받을까? 주식을 시작하면서 항상 느끼는 건 세상이 정말 빠르게 변하고 있다는 것이다. 특히 AI가 나온 뒤로는 기술력 발전 속도를 따라 갈 수가 없다. 나름 슈카월드 이런것들을 챙겨보면서 꾸준히 지식을 습득하려고 하긴 하지만, 그래도 쉽지 않다.
교보문고를 자주 찾아가는건 좋은 습관인 것 같다. 이번 주제에서 분석했듯이 최근 트렌드에 대한 힌트를 책을 읽지 않아도 알 수 있기 때문이다. 물론 소설 부분에 있어서는 대략적인 트렌드를 파악하긴 어렵긴 하지만, 경제나 정치 과학 분야는 쉽게 트렌드를 파악할 수 있다.
분석하면서 데이터에 대한 아쉬움이 조금 느껴졌다. 연령대별로 베스트셀러가 나뉘어져 있었다면, 더 세분화된 분석을 진행할 수 있었을텐데 말이다. 예를 들면 코로나때 20 ~ 30대의 주식에 대한 관심이 많아지기도 했는데, 이는 10대들도 마찬가지였다. 예전에 공모전에 참가해서 10대들을 위한 경제교육 플랫폼을 만들면서, 10대들이 주식에 관심이 있다는 뉴스만 보고 그렇구나 판단하고 따로 데이터로 검증하진 않았는데 이번에 만약 연령대별로 나눠진 베스트셀러 데이터가 있었다면 그런 분석을 더 할 수 있었을텐데 하는 생각이 들었다.
최종코드
# 라이브러리
!pip install koreanize_matplotlib
import koreanize_matplotlib
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import math
import warnings
warnings.filterwarnings('ignore')# 데이터 결합
data = pd.read_excel('/content/drive/MyDrive/공모전/블로그/베스트셀러 데이터/교보문고_종합_베스트셀러_상품리스트 2015.xlsx')
data['연도'] = 2015
for year in range(2016, 2025):
tmp = pd.read_excel(f'/content/drive/MyDrive/공모전/블로그/베스트셀러 데이터/교보문고_종합_베스트셀러_상품리스트 {year}.xlsx')
tmp['연도'] = year
data = pd.concat([data, tmp])
data = data.reset_index(drop = True)# 데이터 전처리
# 필요 컬럼 추출
data = data[['순위', '상품명', '분야', '연도']]
# 50위만 추출
top_50_data = data.loc[data['순위'] <= 50]
# 분야별 그룹화
grouped = top_50_data.groupby(['연도'])['분야'].value_counts().reset_index()
# 피벗테이블 생성
df_pivot = grouped.pivot(index='연도', columns='분야', values='count')# 시각화
categories = df_pivot.columns.tolist()
n = len(categories)
cols = 5
rows = math.ceil(n / cols)
fig, axes = plt.subplots(rows, cols, figsize=(20, rows*3))
axes = axes.flatten()
for i, category in enumerate(categories):
ax = axes[i]
ax.plot(df_pivot.index, df_pivot[category], marker='o')
ax.set_title(f"연도별 '{category}' 분야 베스트셀러 갯수")
ax.set_xlabel('연도')
ax.set_ylabel('count')
for j in range(i+1, len(axes)):
axes[j].axis('off')
plt.tight_layout()
plt.show()'데이터분석 > 일상' 카테고리의 다른 글
| 배민커넥트 퇴근은 언제 해야 할까? 데이터로 콜사구간 예측해서 퇴근 타이밍 정하기 (0) | 2026.01.18 |
|---|---|
| 1년 중 지출이 가장 큰 달은 언제일까? 돈 귀한 줄 몰랐던 날의 나를 반성하기 (0) | 2026.01.11 |
| 점점 빨리 나오는 전어와 방어! 수온 상승의 영향 때문일까? (0) | 2025.11.30 |
| 여름 휴가철 숙박비 인상률이 가장 높은 지역은 어디일까? (9) | 2025.08.17 |
| 이번 여름 휴가는 어디로 갈까? 톨게이트 통행량으로 알아본 인기있는 휴가장소 (9) | 2025.08.10 |



