
주제 선정 배경
최근 이재명 정부의 정책으로 시행된 민생회복 소비쿠폰 15만원! 저도 저번 주에 신청해서 받았는데요. 받은 지 일주일도 안 돼서 다 써버렸습니다. 더치페이할 때 제가 먼저 결제하는 바람에 소비쿠폰이 정말 순식간에 사라지더라고요.
소비쿠폰을 어디에 썼는지 돌아보면, 술집, 편의점, 빵집, 식당 등 대부분 먹는 데에 썼더라고요. 그런데 문득 이런 생각이 들었습니다. "나만 소비쿠폰을 먹는 데 썼나?" 저야 원래 먹는 걸 워낙 좋아하니까 그렇다 쳐도, 다른 사람들도 저처럼 소비쿠폰을 먹는 것 위주로 쓰려는 경향이 있었을까? 아니면 다른 데 더 쓰고 싶어했을까? 확인하고 싶어졌습니다.
사람들은 소비쿠폰을 어디에 쓰고 싶어 할까?
한번 확인해 보자
분석 아이디어
사람들이 소비쿠폰을 사용하기 전에 소비쿠폰 사용 가능 여부를 확인하기 위해 인터넷에 검색을 해볼 것이라고 생각했다. 예를 들어 편의점에서 소비쿠폰을 사용하기 전에 "소비쿠폰 편의점" 과 같은 형식으로 검색을 해보고 편의점에 방문할 것이라고 생각한 것이다.
따라서 "배달", "도서", "의료" 등 소비쿠폰 사용처별 검색량을 수집해서 어떤 키워드의 검색량이 가장 높은 지 확인하는 방식으로 분석을 진행하려고 한다.
활용 데이터
- 구글 트렌드 API
- 구글 트렌드 API는 네이버 트렌드와 달리 키워드 간 검색량 비교가 가능하다. 나의 목표는 키워드별로 검색량의 차이가 얼마나 있는 지를 확인하는 것이기 때문에 구글 트렌드 API를 이용했다.
분석 과정 및 결론
1. 수집할 검색어 설정
먼저 검색량 데이터를 확보할 검색어를 정했다. 최근 정부에서 발표한 아래 그림의 소비쿠폰 사용 가능 업종과, 사용 불가능 업종을 포함시켰다.

거기에 추가적으로 내 생각에 사람들이 관심있어 할만한 업종들까지 추가했다. 그 결과 최종적으로 선정한 검색어는 다음과 같다.
# 검색어 지정
keyword = [
"시장", "마트", "식당", "의류", "미용", "안경", "학원", "약국", "병원",
"편의점", "카페", "치킨", "피자", "술집", "빵집", "이마트", "백화점",
"면세점", "명품", "핸드폰", "전자제품", "쿠팡", "보험", "서점"
]
2. 검색량 데이터 수집
검색어를 전부 다 집어넣고 한 번에 데이터를 수집할 수 있으면 좋겠지만, 아쉽게도 구글 트렌드는 최대 5개 검색어들 간의 검색량만 비교가 가능하다. 어떻게 할 지 고민을 하다 내가 선택한 방법은 검색량이 가장 많은 검색어를 계속 포함시킨 뒤 나머지 4개의 검색어들만 바꿔가면서 데이터를 수집하고, 마지막에 최종적으로 해당 데이터프레임들을 합치는 작업을 진행하기로 했다.
여러 검색어들 중 가장 많은 검색량을 가진 단어는 "배달"이었는데, 처음에는 [배달, 시장, 마트, 식당, 의류] 검색어들 간의 검색량을 수집하고, 다음 루프에서는 [배달, 미용, 안경, 학원, 약국] 검색어들 간의 검색량을 수집해 나가는 방식으로 진행한 것이다. 그렇게 아래와 같은 데이터를 수집할 수 있었다. 날짜는 소비쿠폰 신청을 받기 시작한 7월 21일 부터 8월 1일 까지 수집했다.

3. 데이터 전처리
분석에 필요하지 않은 변수인 아직 구글트렌드 자체에서 검색량 데이터 정리를 끝마치지 못한 상태를 나타내는 isPartial 변수를 제거했다.

그 다음 기준값으로 설정한 검색어인 "배달"은 1개만 필요하기 때문에 평균으로 대체한 새로운 컬럼을 1개 만들고 나머지는 모두 제거했다.
# 검색량 기준값 계산 추가 및 기존 컬럼 삭제
final_df['소비쿠폰 배달앱'] = final_df['소비쿠폰 배달'].mean(axis = 'columns').round().astype(int)
final_df = final_df.drop('소비쿠폰 배달', axis = 1)
마지막으로 시각화 했을 때 컬럼명을 편하게 보기 위해서 컬럼들 앞에 붙은 "소비쿠폰"이라는 단어는 제거해줬다. 그렇게 최종적으로 아래와 같은 데이터프레임을 만들었다.

4. 시각화
수집한 데이터의 컬럼별 평균을 이용해 아래와 같은 그래프를 그렸다. X축은 검색량 평균, Y축은 검색어를 나타낸다.
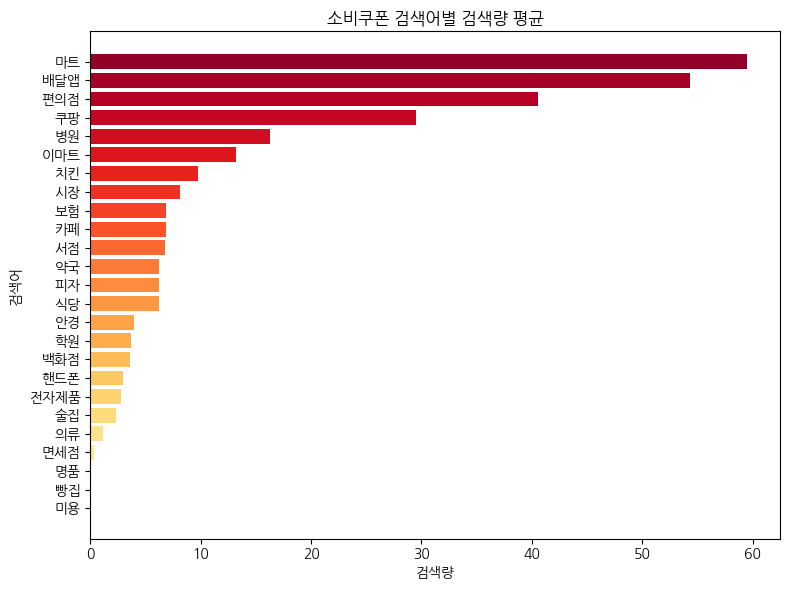
결과를 확인해보면 마트, 배달앱, 편의점, 쿠팡 순으로 검색량이 높았다. 역시 나만 먹는 것에 사용하려고 하는 것은 아니었다. 가장 접근성이 좋은 음식에 소비쿠폰을 사용하려는 사람들이 많은 것 같다.
추가적으로 여기서 배달앱이 검색량이 가장 많아서 배달앱을 기준값으로 잡았는데 왜 마트가 검색량이 더 높냐고 궁금증이 생길 수 있다. 구글트렌드는 입력한 검색어들 중에서 가장 많은 검색량을 가진 날의 값을 100으로 설정하고 나머지 값은 그에 대한 상대적인 검색량을 부여한다. 예를 들어, 7월 22일에 배달앱의 검색량이 가장 높다면 그 날을 100으로 잡고, 7월 24일 마트의 검색량이 7월 22일 배달앱 검색량의 절반 정도가 된다면 50을 부여하는 방식이다. 내가 수집한 데이터에서 7월 26일의 배달앱 검색량이 100이었으므로 전혀 문제될 것이 없다.
5. 결론
사람들은 소비쿠폰을 마트, 배달앱, 편의점, 쿠팡 등 식료품이나 생활용품에 사용하고 싶어한다.
쿠키
생각해보면 2020년에도 이와 비슷한 방식으로 지원금 정책을 펼쳤었다. "코로나 재난지원금"
나는 코로나 재난지원금때도, 위에서 분석한 소비쿠폰과 사용처가 비슷했을 지 확인하고 싶어졌다.
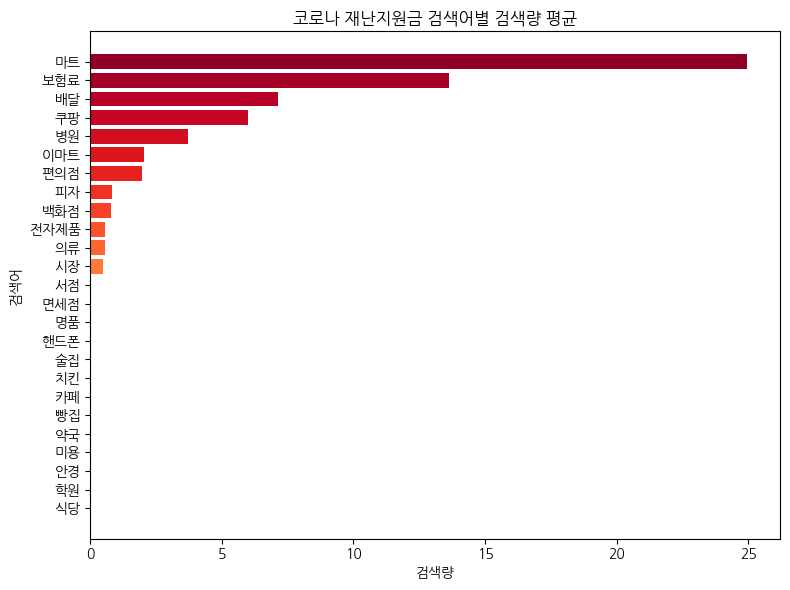
같은 방식으로 확인해 본 결과, 소비쿠폰과 비슷하게 마트, 배달앱, 쿠팡의 검색량이 굉장히 높았다. 그때나 지금이나 사람들이 사용하고 싶어하는 곳은 비슷하다.
의외인 것은 보험료와 병원의 검색량이 굉장히 높게 나왔다는 것인데, 이것은 소비쿠폰에서도 비슷한 모습을 찾아볼 수 있었다. 소비쿠폰의 경우에도 보험료와, 병원의 검색량이 꽤 높게 나왔었다. 먹는 것 다음으로, 건강을 생각하는 성향이 있는 것 같다.
마무리
아쉽게도 사람들이 소비쿠폰을 사용하고 싶어하는 곳 대부분은 정부가 사용하지 못하도록 막아 놓았다. 배달앱, 쿠팡, 마트 등등... 지역화폐를 사용할 수 있는 배달앱인 땡겨요의 MAU가 전월 대비 50%나 증가한 것만 봐도 사람들이 얼마나 소비쿠폰을 배달앱에 사용하고 싶어하는 지 알 수 있다.
물론 정부가 소비 쿠폰이 특정 대기업 플랫폼에 집중되는 현상을 경계하는 의도로 이렇게 정책을 시행했는 지는 알겠지만 그래도 기존에 사용하던 어플이 아닌 다른 어플을 설치하고, 가입하고 하는 등의 불편함에 아쉬운 마음이 드는 것은 어쩔 수 없다.
최종코드
# 라이브러리
!pip install pytrends
!pip install koreanize_matplotlib
import koreanize_matplotlib
from pytrends.request import TrendReq
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import requests
import json# 데이터 수집 및 전처리
final_df = pd.DataFrame()
# 검색어 지정
keyword = [
"시장", "마트", "식당", "의류", "미용", "안경", "학원", "약국", "병원",
"편의점", "카페", "치킨", "피자", "술집", "빵집", "이마트", "백화점",
"면세점", "명품", "핸드폰", "전자제품", "쿠팡", "보험", "서점"
]
# 소비쿠폰 텍스트 추가
text_keyword = ["소비쿠폰 " + x for x in keyword]
# pytrends 객체 생성
pytrends = TrendReq(hl = 'ko', tz = 540)
start_date = '2025-07-22'
end_date = '2025-07-26'
timeframe = f"{start_date} {end_date}"
# 데이터 수집
for i in range(0, len(text_keyword), 4):
batch = text_keyword[i: i + 4]
# 검색량 기준이 되는 "소비쿠폰 배달" 키워드 추가
batch += ['소비쿠폰 배달']
pytrends.build_payload(batch, timeframe = timeframe, geo = 'KR')
dat = pytrends.interest_over_time()
final_df = pd.concat([final_df, dat], axis = 1)
# 최종 데이터프레임 정리
final_df = final_df.drop('isPartial', axis = 1)
# 검색량 기준값 계산 추가 및 기존 컬럼 삭제
final_df['소비쿠폰 배달앱'] = final_df['소비쿠폰 배달'].mean(axis = 'columns').round().astype(int)
final_df = final_df.drop('소비쿠폰 배달', axis = 1)
# 컬럼명 정리
final_df.columns = keyword + ['배달앱']
final_df.head()# 시각화
df = final_df.mean().sort_values()
colors = sns.color_palette("YlOrRd", len(df))
plt.figure(figsize = (8, 6))
plt.barh(df.index, df.values, color = colors)
plt.title('소비쿠폰 검색어별 검색량 평균')
plt.xlabel('검색량')
plt.ylabel("검색어")
plt.tight_layout()
plt.show()'데이터분석 > 경제' 카테고리의 다른 글
| “동네 아주머니가 주식 사면 고점이다?” 데이터로 밈 검증해보기! (0) | 2025.12.14 |
|---|---|
| 대형마트와 편의점의 물건 가격차이가 통계적으로 유의할까? (2) | 2025.06.29 |
| 배달수수료 vs 코로나 vs 전쟁, 늘어가는 음식점 폐업의 원인은 무엇일까? (4) | 2025.05.11 |
| 고물가 시대, 실제로 어떤 상품의 가격이 가장 많이 올랐을까? (3) | 2025.04.06 |
| 고갈위기 국민연금, 과연 나는 받을 수 있을까? (1) | 2025.03.30 |



