
주제 선정 배경
헌정 사상 2번째로 대통령이 파면되었다. 그 결과 2025년 6월 3일 조기대선을 치루게 되었다. 비상계엄 선포 이후 국민들 특히 20대가 정치에 관심을 많이 갖게 된 것 같다. 내 주변 사람들만 그런 것인지는 모르겠지만 요즘 술자리를 가지면 정치나 경제 이야기가 많이 나오는 것 같다.
이런 정치적인 정보는 보통 유튜브나 인터넷 검색을 통해 얻는다. 대선이 가까워 지고 있는 만큼 나 또한 대통령 후보로 거론되는 인물들의 이름을 검색하기 시작했다.
그러다 문득 역대 대통령 선거에서 선거기간 동안 가장 많이 검색된 대통령 후보가
실제로 당선됐을지 궁금해졌다. 한번 확인해 보자.
활용 데이터
- 역대 대통령 선거 데이터
- 따로 데이터가 존재하지 않아서 직접 검색해서 수집했다.
- 지난 대통령 선거의 선거일, 후보, 당선자가 포함되어있다.
- 구글 트렌드 데이터
- 파이썬으로 구글 트렌드 데이터를 불러올 수 있는 pytrends 라는 비공식 API로 수집했다.
- 키워드들을 입력하면 해당 키워드 그룹 내에서의 상대적인 검색량을 비교할 수 있다.
- 네이버 트렌드 데이터 - 네이버 데이터랩
- 네이버 트렌드 API를 이용하여 수집했다.
- 구글 트렌드와는 달리 해당 검색어가 꾸준한 관심을 받고 있는지에 관한 정보를 제공한다.
- 구글과 네이버의 사용자 특성이 다르기 때문에 비교를 위해 수집했다.
분석 과정 및 결론
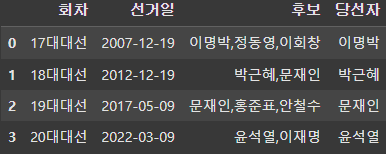
1. 지난 대선 데이터 수집
구글 트렌드는 2004년부터의 검색 트렌드 데이터만 제공한다. 따라서 2004년 이후에 치뤄진 대선인 17대 대선부터 데이터를 수집했다.
2. 각 대선별 후보자 검색량 데이터 수집
구글 트렌드는 절대적인 검색량을 제공하는 것이 아닌 입력 키워드들 간의 상대적인 검색량 비교만 제공한다. 예를들어 윤석열, 이재명을 키워드로 입력하면 윤석열의 검색량과 이재명의 검색량을 비교해서 상대적인 비율로 표시해준다는 것이다.
대선 회차별로 후보간 검색량 차이 데이터를 수집했다. 선거관리 위원회에서 말하고 있는 대통령 선거기간은 선거일 기준 23일 전부터 이므로 해당 기간의 검색 데이터를 수집했다.

3. 각 대선별 후보자 간 검색량 시각화
대선별로 후보자간 검색량 데이터를 시각화 한 후 해당 대선의 실제 당선자는 "당선자"로 표시했다. X축은 후보, Y축은 구글 트렌드로 수집한 검색량 데이터이다.
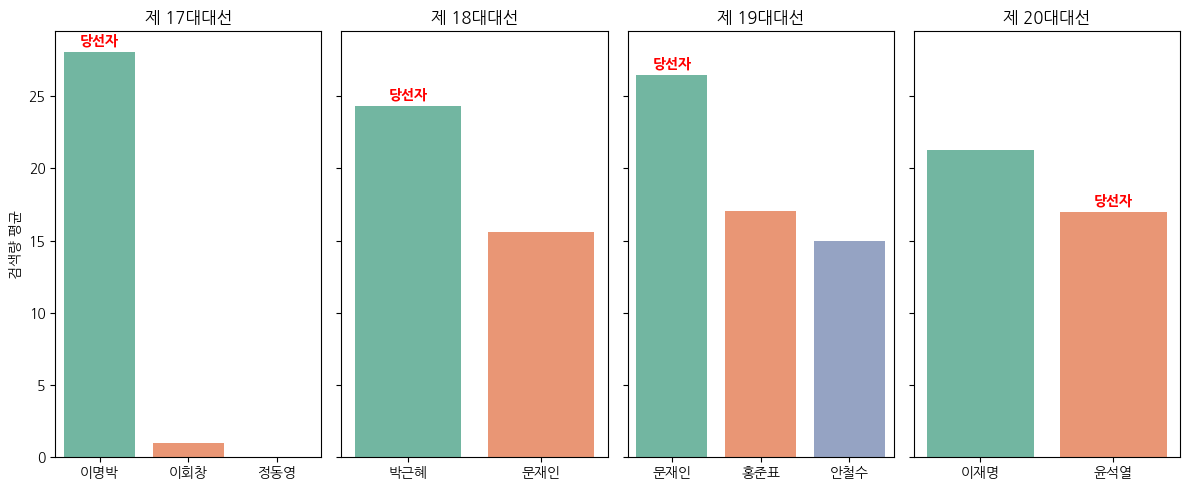
20대 대선을 제외한 모든 대선이 검색량이 가장 많았던 후보가 실제로 대통령에 당선되었다.
신기했다. 20대 대선도 같은 결과였다면 더 좋았겠다 라는 생각이 스치는 순간 20대 대선때 윤석열과 안철수가 단일화 했다는 사실이 떠올랐다. 그래서 이재명, 윤석열, 안철수를 키워드로 집어넣고 다시 검색량을 비교해봤다.
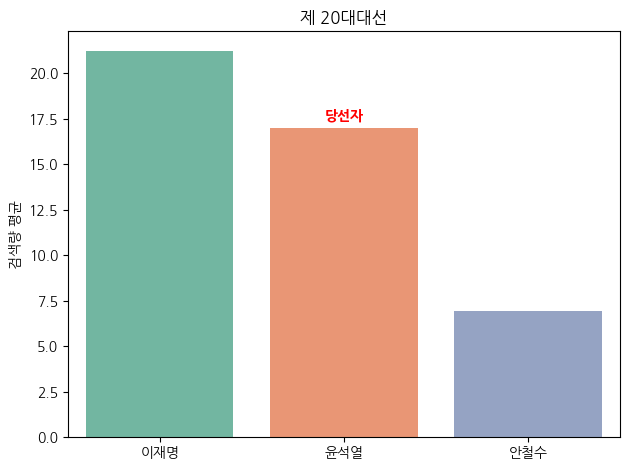

단일화로 인해 안철수의 표가 윤석열로 상당 수 넘어갔을 것이라 생각하면 20대 대선또한 검색량이 가장 많은 후보가 당선된 것이라 생각할 수 있을 것 같다.
4. 네이버 트렌드 데이터로 확인한 결과
네이버 트렌드 데이터는 2016년 1월 데이터부터 제공하므로 2017년에 치뤄진 19대 대선과 2022년에 치뤄진 20대 대선 2가지만 확인할 수 있었다.
구글 트렌드와 네이버 트렌드의 차이점은 후보 간 검색량 비교가능 여부이다. 네이버 트렌드의 경우 윤석열, 이재명을 키워드로 입력하면 윤석열 100 이재명 50 이런식으로 제공하는 것이 아닌 두 검색어의 검색량 평균인 75를 제공해준다. 따라서 네이버 트렌드는 두 후보 간 검색량 비교가 불가능하다.
그래서 각 키워드를 따로 입력해서 검색량 평균을 계산했다. 이렇게 되면 각 후보의 검색량 평균이라는 지표를 꾸준히 높은 관심을 받고 있는지로 해석할 수 있다. 즉, 아래 그래프의 검색량 평균이 높은 사람은 선거기간동안 네이버에서 꾸준한 관심을 받은 후보자라고 판단할 수 있다.

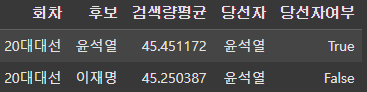
그 결과 네이버에서 꾸준한 관심을 많이 받은 후보가 실제로도 대통령으로 당선되었다. 특히 구글 트렌드와 달리 20대 대선에서 단일화를 실시한 안철수와 윤석열의 검색량을 합하지 않았는데도 실제 당선자인 윤석열이 이재명보다 꾸준한 관심을 받았었다.
마지막으로 구글 트렌드 검색량과 네이버 트렌드 검색량을 합하면 윤석열의 검색량이 0.2정도 앞선다. 표차이 0.73%로 역대 가장 치열했던 20대 대선이었던 만큼 검색량의 차이도 미세했다.
선거기간 중 가장 많이 검색된 대통령 후보가 실제로 당선되었다.
국민들은 투표용지에 쓸 이름을 검색창에 먼저 썼다.
쿠키
검색량으로 본 21대 대통령 선거 결과 예측
본투표만을 남겨두고 있는 21대 대선은 이재명, 김문수, 이준석의 3자 구도로 진행중이다. 과연 이들 중 대통령으로 당선되는 사람은 누구일까?
선거운동이 시작된 2025년 5월 12일 부터 오늘(2025년 6월 1일)까지의 검색량 데이터를 수집했다.
1. 구글 트렌드를 이용한 예측 결과

구글 트렌드에서 가장 높은 검색량을 보이는 것은 이재명이다. 윤석열의 계엄사태 여파가 반영됐을 것으로 생각된다. 이준석의 검색량이 김문수 보다 높다는 것은 의외의 결과였다. 이번 대선을 통해 정치계의 젊은피, 새로운 보수로 완전히 자리잡게 될지 궁금해진다.
2. 네이버 트렌드를 이용한 예측 결과

네이버 트렌드를 통해 파악한 꾸준한 관심을 받고 있는 후보 또한 이재명이었다. 그리고 여기서도 이준석이 김문수 보다 꾸준한 관심을 받고 있었다.
마무리
선거철만 되면 전화기가 불타기 시작한다. 여론조사, 선거유세, 투표독려 등 잊을만 하면 전화기가 울려댄다. 이런식으로 수집된 정보를 이용해 선거기간 내내 지지율이 이렇다 저렇다 이야기 한다. 이번에 만든 검색량 지표도 꽤 훌륭한 여론조사 수단이 될 것으로 보인다. 생각보다 정확도가 좋다. 나이대별로 분리가 가능한 네이버 트렌드를 이용해 연령별 지지율도 살펴볼 수 있을 것 같고, 이런 지표는 각 후보의 선거캠프에서 유용하게 사용할 수 있을 것 같다. 또, 여론조사의 중요성을 느꼈던게 지난 미국의 대선이었다. 당선 후보만 잘 예측했다면 100%에 달하는 수익을 얻을 수 있었을텐데...
최종코드
# 구글 트렌드 API 라이브러리 설치
!pip install pytrendsfrom pytrends.request import TrendReq
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import timedelta
from datetime import date
import time
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)# 검색량 데이터 수집
# pytrends 객체 생성
pytrends = TrendReq(hl = 'ko', tz = 540)
results = []
for index, row in data.iterrows():
election_date = pd.to_datetime(row['선거일'])
# 선거기간은 선거일 기준 23일 전부터 당일까지임
start_date = (election_date - timedelta(days = 23)).strftime('%Y-%m-%d')
end_date = election_date.strftime('%Y-%m-%d')
timeframe = f"{start_date} {end_date}"
candidates = [c.strip() for c in row['후보'].split(',')]
for i in range(0, len(candidates), 5):
batch = candidates[i:i+5]
try:
time.sleep(5)
pytrends.build_payload(batch, timeframe = timeframe, geo = 'KR')
dat = pytrends.interest_over_time()
if not dat.empty:
# 후보별 평균 검색량 계산
mean_search = dat[batch].mean()
for name, value in mean_search.items():
results.append({
'회차' : row['회차'],
'당선자' : row['당선자'],
'후보' : name,
'검색량평균' : round(value, 2)
})
except Exception as e:
print(f"{row['회차']}회차, 후보 {batch} 검색 중 오류 발생: {e}")# 결과를 데이터프레임으로 변환
search_df = pd.DataFrame(results)
# 검색량 높은 순 정렬
search_df.sort_values(['회차', '검색량평균'], ascending=[True, False], inplace=True)
search_df.reset_index(drop=True, inplace=True)
# 검색량 1위 여부, 당선 여부 추가
search_df['검색량1위'] = search_df.groupby('회차')['검색량평균'].transform('max') == search_df['검색량평균']
search_df['당선자여부'] = search_df['후보'] == search_df['당선자']
# 결과 확인
search_df# 시각화
# 대선 회차 목록
rounds = search_df['회차'].unique()
# subplot 그리기
fig, axes = plt.subplots(1, len(rounds), figsize=(12, 5), sharey=True)
for i, round_num in enumerate(rounds):
ax = axes[i]
data = search_df[search_df['회차'] == round_num]
# 막대 그래프
sns.barplot(x='후보', y='검색량평균', data=data, ax=ax, palette='Set2')
# 당선자 텍스트 표시
for idx, row in data.iterrows():
if row['당선자여부']:
ax.text(x=data.index.get_loc(idx),
y=row['검색량평균'] + 0.3,
s='당선자',
ha='center',
va='bottom',
fontsize=10,
color='red',
fontweight='bold')
ax.set_title(f'제 {round_num}')
ax.set_ylabel('검색량 평균')
plt.tight_layout()
plt.show()# 네이버 트렌드 API
url = "https://openapi.naver.com/v1/datalab/search"
headers = {
"X-Naver-Client-Id": client_id,
"X-Naver-Client-Secret": client_secret,
"Content-Type": "application/json"
}
dat = []
for idx in range(2, len(data)):
keywordGroups = []
for candidate in data['후보'][idx].split(','):
keywordGroups.append({
"groupName" : candidate,
"keywords" : [candidate]
})
# 요청값
body = {
"startDate": (data['선거일'][idx] - timedelta(days = 23)).strftime("%Y-%m-%d"),
"endDate": data['선거일'][idx].strftime("%Y-%m-%d"),
"timeUnit": "date",
"keywordGroups": keywordGroups
}
response = requests.post(url, headers=headers, json=body)
if response.status_code == 200:
response = response.json()
for result in response['results']:
title = result['title']
ratios = [entry['ratio'] for entry in result['data']]
avg_ratio = sum(ratios) / len(ratios)
dat.append({
'회차' : data['회차'][idx],
'후보' : title,
'검색량평균' : avg_ratio,
'당선자' : data['당선자'][idx]
})
else:
print("Error Code:", response.status_code)