
주제 선정 배경
저는 50만 쉬었음단 중 1명으로 취업을 위해 열심히 공부하고, 스펙쌓고 하고 있는데요. 학교를 졸업하고 백수가되어 가장 크게 느끼는 부분은 요일에 대한 개념이 흐려졌다는 겁니다. 출퇴근이 없으니 "월요병"도 자연스럽게 사라졌고, 일주일이 그저 똑같은 하루처럼 느껴지기 시작했어요.
그런데 문득, 저와는 달리 여전히 바쁘게 일상을 살아가는 직장인들은 과연 일주일 중 언제가 가장 힘들까 궁금해졌어요. 정말 "월요병"이라는 말처럼 월요일이 가장 힘들고 우울한 날일까, 아니면 월요일이 아닌 다른 요일이 더 퇴사 욕구를 자극하는 날일까? 확인해 보고 싶어졌습니다.
직장인들이 가장 퇴사 마려운 요일은 언제일까?
한번 확인해 보자
활용 데이터
- 요일별 직장인 커뮤니티 블라인드에 "퇴사하고 싶다"는 내용으로 게시된 글의 갯수
- 블라인드는 직장인들이 자신의 속마음을 털어놓거나, 궁금한 것들에 대해 질문할 수 있는 커뮤니티다.
- 데이터를 제공하는 API가 없으므로 Selenium과 beautifulsoup를 이용해 직접 크롤링 했다.

분석 과정 및 결론
1. 블라인드 데이터 수집
블라인드에서 데이터를 수집하기 위해서 HTML 파싱 라이브러리인 beautifulsoup를 이용했다. 또 테스트 자동화 프레임워크인 셀레니움(Selenium)도 사용했다. 셀레니움을 사용한 이유는 블라인드의 게시글들이 1페이지, 2페이지 이런식으로 URL을 이용해서 구분된 것이 아닌 스크롤을 끝까지 내리면 목록이 업데이트 되는 식으로 구성되어 있었기 때문이다. 그래서 Selenium을 이용하여 스크롤을 자동화하고 게시글을 최대한 많이 업데이트 시킨 뒤 beautifulsoup를 이용해 HTML 요소를 파싱하는 방식으로 데이터를 수집했다.
최종적으로 '퇴사하고 싶다'는 의견을 확인하기 위해 글의 제목과 글의 내용을 수집했고, 무슨요일에 글을 게시했는지 확인하기 위해 글의 작성일자를 수집해 데이터프레임 형태로 저장했다.

2. 데이터 전처리
비밀글 같이 공개가 제한된 게시글이 존재했다. 이 글들은 결측치라 판단해 데이터에서 제거했다.
data.loc[data['작성일자'].isnull()]
블라인드의 작성일자같은 경우 몇분전, 몇시간전, 어제, 몇일전, 03.04, 2022.04.03와 같이 총 6가지 형식이 존재한다. 몇분전, 몇시간전의 형식은 오늘날짜로 변환하고, 어제는 어제날짜, 몇일전은 몇일전날짜, 03.04형식은 올해연도를 추가해 2025-03-04로 변환하여 모든 작성일자를 YYYY-MM-DD 형식으로 통일시켰다.
# 분이 포함된 작성일자는 오늘날짜로 저장
data.loc[data['작성일자'].str.contains('분'), '작성일자'] = datetime.today().date()
# 시간이 포함된 작성일자는 오늘날짜로 저장
data.loc[data['작성일자'].str.contains('시간'), '작성일자'] = datetime.today().date()
# 어제가 포함된 작성일자는 어제날짜로 저장
data.loc[data['작성일자'].str.contains('어제', na = False), '작성일자'] = datetime.today().date() - timedelta(days = 1)
# '일' 앞의 숫자를 추출해서 작성일자 값을 수정
mask = data['작성일자'].str.contains(r'\d+일', na=False)
data.loc[mask, '작성일자'] = data.loc[mask, '작성일자'].str.extract(r'(\d+)').astype(int)[0].apply(
lambda x: (datetime.today().date() - timedelta(days=x))
)
# 올해 데이터는 연도표시가 안됨 -> 연도표시 해줌
current_year = datetime.today().year # 올해 연도
# MM.DD 형식의 문자열만 필터링 (예: 03.02, 12.25)
mask = data['작성일자'].str.match(r'^\d{2}\.\d{2}$', na = False)
# 연도 추가해서 'YYYY-MM-DD' 형식으로 변환
data.loc[mask, '작성일자'] = data.loc[mask, '작성일자'].apply(
lambda x: f"{current_year}-{x.replace('.', '-')}"
)
# 연도를 'YYYY-MM-DD' 형식으로 변환
mask = data['작성일자'].str.match(r'^\d{4}\.\d{2}\.\d{2}\.$', na=False)
# 형식 변환
data.loc[mask, '작성일자'] = data.loc[mask, '작성일자'].str.rstrip('.') \
.str.replace('.', '-', regex=False)
다음으로 판다스의 dayofweek을 이용하여 작성일자의 요일을 새로운 컬럼으로 추가했다.
# 숫자 요일 → 한글 요일로 매핑
day_map = {
0: '월요일', 1: '화요일', 2: '수요일', 3: '목요일',
4: '금요일', 5: '토요일', 6: '일요일'
}
data['요일'] = data['작성일자'].dt.dayofweek.map(day_map)
마지막으로 "퇴사하고 싶다"와 높은 관련성 있는 글만 추출하기 위해 제목에 퇴사가 들어가있거나, 내용에 퇴사하고싶다라는 내용이 포함되어 있는 데이터만 골라냈다.
# 관련 없는 글 제거
# 정규표현식 패턴: 퇴사하고싶다
pattern = r'퇴\s*사\s*하\s*고\s*싶\s*다'
data = data.loc[data['제목'].str.contains('퇴사') | data['내용'].str.contains(pattern, regex=True)]
3. 요일별 글 갯수 카운팅 및 시각화
판다스의 value_counts를 이용해 요일별 글의 갯수를 카운팅 한 뒤 시각화 하여 분석결과를 확인했다.
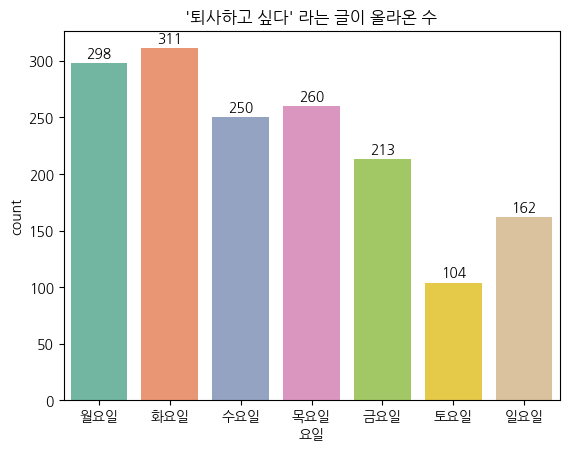
놀랍게도 퇴사하고 싶다는 글이 가장 많이 올라온 요일은 화요일이었다. 이유를 한 번 생각해봤다.
월요일은 주말동안 회복한 에너지를 이용해 "이번 주도 잘 버텨보자"라는 각오로 출근하기 때문에 화요일에 비해 활기찬 하루를 보낼수도 있단 생각이 들었다. 그렇기 때문에 어중간한 화요일이 가장 희망이 없는 요일로 체감되기에 이런 결과가 나온 것 같다.
그리고 토요일과 일요일에 꽤 유의미한 차이가 보이는 것을 확인할 수 있었는데 나는 이게 조금 재밌었다. 토요일에 직장인은 정말 행복해 하는 반면, 일요일은 이제 내일 출근해야 된다는 생각에 퇴사하고 싶다는 생각을 하는 것 같았다. 역시 사람들 하는 생각이 다 똑같다.
많은 사람들이 '월요병'을 말하지만, 실제로 퇴사 욕구가 폭발하는 요일은 화요일이었다.
직장인에게 화요일은 가장 무기력하고 절망적인 요일이다.
이젠 월요병이 아니라 화요병이다.
쿠키
추가로 직장인들의 애환이 담긴 "퇴근하고 싶다" 는 내용의 글과 "집가고 싶다" 는 내용의 글 갯수 또한 확인해봤다.

역시나 월요일 보다는 화요일에 "퇴근하고 싶다", "집가고 싶다" 라는 내용의 글이 많이 올라왔다. 특이한 점은 "퇴사하고 싶다" 와는 달리 금요일에도 글이 많이 올라왔다는 점인데, 불금에 약속이 잡혀있어 빨리 퇴근하고 놀고 싶다거나, 주말이 기대되는 마음에 빨리 퇴근해서 집가고 싶다는 간절한 마음이 투영된 것으로 보인다.
글의 실제내용을 살펴보다가 금요일에 야근때문에 집가고 싶다는 글이 많이 올라오는 걸 보고 눈물을 감출 수 없었다. 대한민국 직장인들 다들 힘내세요... 저도 직장인이 되는 날까지 열심히 노력해보겠습니다!
마무리
직장인이 가장 우울해 하는 요일인 화요일에 회사차원에서 복지를 늘리면 도움이 될 것 같다는 생각이 들었다. 무료 커피나 간식, 급식의 수요일에 맛있는 음식이 나오는 것처럼 화요일에 더 특별한 식사를 제공하거나 하는 방식으로 복지를 제공하는 것도 좋아보인다. 또, 요즘보면 금요일에 퇴근을 1시간정도 일찍하는 제도를 도입하는 회사들이 있는데 화요일이랑 반반나눠서 30분씩 일찍 퇴근하는 제도도 좋아보인다. 아니면 화요일마다 경품추첨 행사..? 로또를 사놓고 1주일을 버티는 것처럼 화요일을 기다리지 않을까..? 아직 백수라 직장인의 정확한 마음은 모르겠지만 일단 지금 생각으로는 밥 맛있는게 짱이다.
최종코드
!pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Optionsimport time
from datetime import datetime
from datetime import timedelta
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")# 셀레니움으로 스크롤 자동화
# 크롬 옵션 설정 (필요에 따라 headless 가능)
chrome_options = Options()
chrome_options.add_argument("--start-maximized")
# 크롬 드라이버 경로 설정 (예: C:/chromedriver/chromedriver.exe)
driver_path = "C:/Users/master/chromedriver/chromedriver.exe" # 본인 경로로 수정
# 드라이버 실행
service = Service(driver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
# 페이지 접속
url = "https://www.teamblind.com/kr/search/퇴사하고싶다"
driver.get(url)
# 로딩 대기
time.sleep(3)
SCROLL_PAUSE_TIME = 2
last_height = driver.execute_script("return document.body.scrollHeight")
while True: # 스크롤 내릴 수 없을 때까지 반복
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
print("더 이상 스크롤할 수 없음")
break
last_height = new_height
print("스크롤 완료")# Html 파싱 및 필요 요소 추출 후 데이터프레임 생성
soup = BeautifulSoup(driver.page_source, 'html.parser')
articles = soup.find_all("div", class_="article-list-pre nth-even")
data = []
for article in articles:
# 제목
title_tag = article.find("h3")
title = title_tag.text.strip() if title_tag else ""
# 내용 요약
content_tag = article.find("p", class_="pre-txt")
content = content_tag.text.strip() if content_tag else ""
# 작성일자
date_tag = article.find("a", class_="past")
if date_tag:
# i 태그 제거
if date_tag.i:
date_tag.i.extract()
date = date_tag.text.strip()
else:
date = ""
# 한 줄씩 저장
data.append({
"제목": title,
"내용": content,
"작성일자": date
})
# DataFrame 생성
df = pd.DataFrame(data)
df.head()# 데이터 전처리
# 결측치 제거
data = data.loc[data['작성일자'].notnull()]
# 분이 포함된 작성일자는 오늘날짜로 저장
data.loc[data['작성일자'].str.contains('분'), '작성일자'] = datetime.today().date()
# 시간이 포함된 작성일자는 오늘날짜로 저장
data.loc[data['작성일자'].str.contains('시간'), '작성일자'] = datetime.today().date()
# 어제가 포함된 작성일자는 어제날짜로 저장
data.loc[data['작성일자'].str.contains('어제', na = False), '작성일자'] = datetime.today().date() - timedelta(days = 1)
# '일' 앞의 숫자를 추출해서 작성일자 값을 수정
mask = data['작성일자'].str.contains(r'\d+일', na=False)
data.loc[mask, '작성일자'] = data.loc[mask, '작성일자'].str.extract(r'(\d+)').astype(int)[0].apply(
lambda x: (datetime.today().date() - timedelta(days=x))
)
# 올해 데이터는 연도표시가 안됨 -> 연도표시 해줌
current_year = datetime.today().year # 올해 연도
# MM.DD 형식의 문자열만 필터링 (예: 03.02, 12.25)
mask = data['작성일자'].str.match(r'^\d{2}\.\d{2}$', na = False)
# 연도 추가해서 'YYYY-MM-DD' 형식으로 변환
data.loc[mask, '작성일자'] = data.loc[mask, '작성일자'].apply(
lambda x: f"{current_year}-{x.replace('.', '-')}"
)
# 연도를 'YYYY-MM-DD' 형식으로 변환
mask = data['작성일자'].str.match(r'^\d{4}\.\d{2}\.\d{2}\.$', na=False)
# 형식 변환
data.loc[mask, '작성일자'] = data.loc[mask, '작성일자'].str.rstrip('.') \
.str.replace('.', '-', regex=False)
# datetime 형식변환
data['작성일자'] = pd.to_datetime(data['작성일자'])
# 숫자 요일 → 한글 요일로 매핑
day_map = {
0: '월요일', 1: '화요일', 2: '수요일', 3: '목요일',
4: '금요일', 5: '토요일', 6: '일요일'
}
data['요일'] = data['작성일자'].dt.dayofweek.map(day_map)
# 관련 없는 글 제거
# 정규표현식 패턴: 퇴사하고싶다
pattern = r'퇴\s*사\s*하\s*고\s*싶\s*다'
data = data.loc[data['제목'].str.contains('퇴사') | data['내용'].str.contains(pattern, regex=True)]# 시각화
df = data.value_counts('요일').reset_index()
# 요일 정렬 기준 정의
day_order = ['월요일', '화요일', '수요일', '목요일', '금요일', '토요일', '일요일']
# 요일 컬럼을 카테고리형으로 변환 후 정렬
df['요일'] = pd.Categorical(df['요일'], categories=day_order, ordered=True)
df = df.sort_values('요일').reset_index(drop=True)
ax = sns.barplot(x='요일', y='count', data=df, palette='Set2')
# 각 bar 위에 count 값 표시
for container in ax.containers:
ax.bar_label(container, fmt='%d', label_type='edge', padding=2)
plt.title('\'퇴사하고 싶다\' 라는 글이 올라온 수')
plt.show()'데이터분석 > 일상' 카테고리의 다른 글
| 나는 언제 배달음식을 시켜 먹을까? 실제 배달주문 데이터로 알아본 배달 땡기는 날 (2) | 2025.06.08 |
|---|---|
| 음식맛을 가르는 결정적인 한 끗, 음식별 킥이 되는 재료는 무엇일까? (3) | 2025.05.25 |
| 이 도시는 뭐가 유명하지? 여행계획 짜기 귀찮아서 만들어본 검색량 기반 꾸준히 인기있는 관광지 찾기 (4) | 2025.05.18 |
| 영상보다 댓글이 먼저인 시대, 댓글을 먼저 보는 행동이 위험하진 않을까? (3) | 2025.04.27 |
| 벚꽃 시즌만 되면 비 오는 것 같은 느낌, 그저 기분 탓일까? (0) | 2025.04.20 |



